
Recent text-to-video (T2V) diffusion models have made remarkable progress in generating high-quality videos. However, they often struggle to align with complex text prompts, particularly when multiple objects, attributes, or spatial relations are specified. We introduce VideoRepair, the first self-correcting, training-free, and model-agnostic video refinement framework that automatically detects fine-grained text-video misalignments and performs targeted, localized corrections. Our key insight is that even misaligned videos usually contain correctly generated regions that should be preserved rather than regenerated. Building on this observation, VideoRepair proposes a novel region-preserving refinement strategy with three stages: (i) misalignment detection, where MLLM-based evaluation with automatically generated evaluation questions identifies misaligned regions; (ii) refinement planning, which preserves correctly generated entities, segments their regions across frames, and constructs targeted prompts for misaligned areas; and (iii) localized refinement, which selectively regenerates problematic regions while preserving faithful content through joint optimization of preserved and newly generated areas. On two benchmarks, EvalCrafter and T2V-CompBench with four recent T2V backbones, VideoRepair achieves substantial improvements over recent baselines across diverse alignment metrics. Comprehensive ablations further demonstrate the efficiency, robustness, and interpretability of our framework.
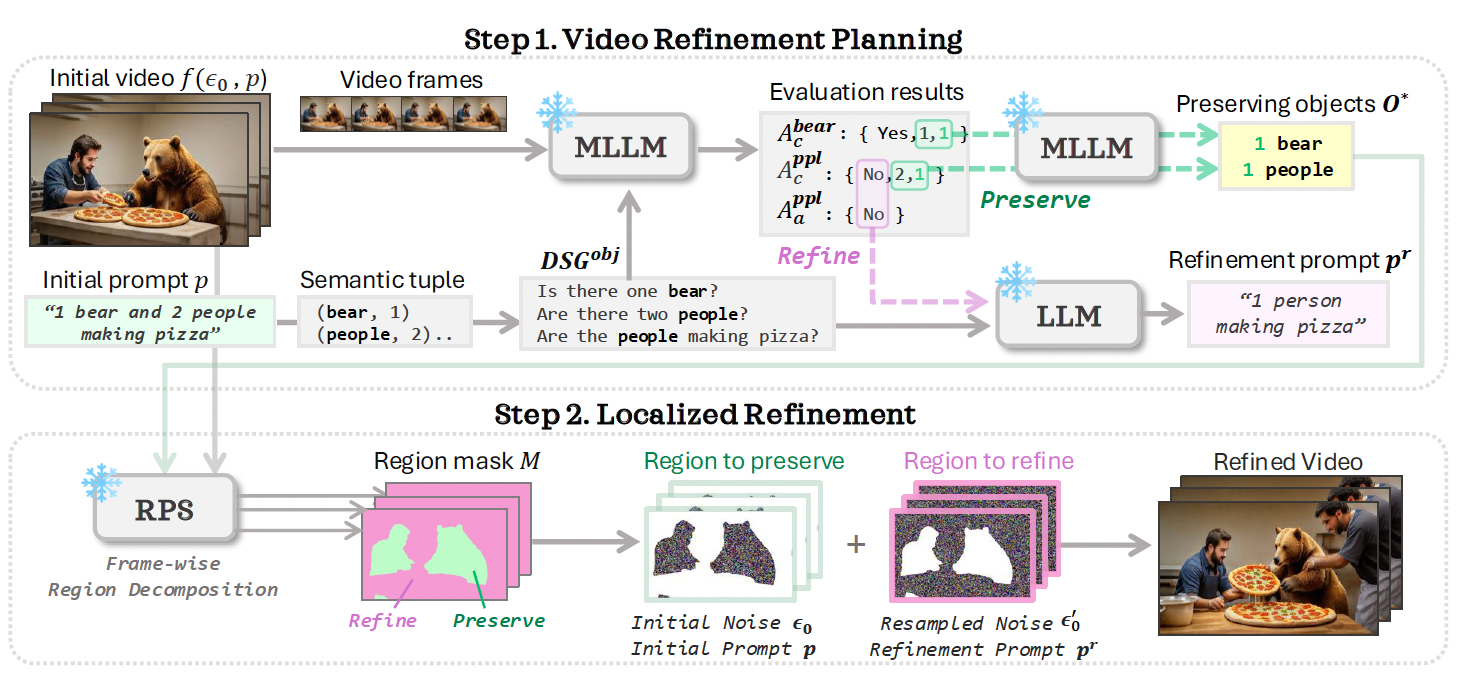
VideoRepair refines the generated video in two stages: (1) video refinement planning (Sec. 3.1), (2) localized refinement (Sec. 3.2). Given the prompt p, we first generate a fine-grained evaluation question set and ask the MLLM to provide answers. Next, we identify accurately generated objects O* and plan the refinement pr of other regions using MLLM/LLM. Based on O*, we determine which regions to preserve or refine using the RPS module. Finally, we apply localized refinement with the original T2V model.






































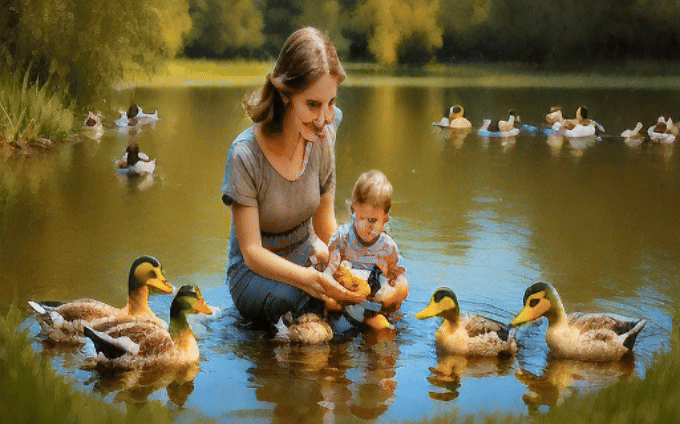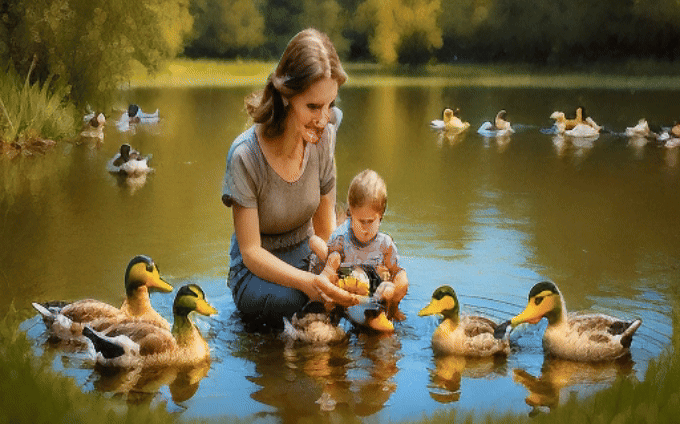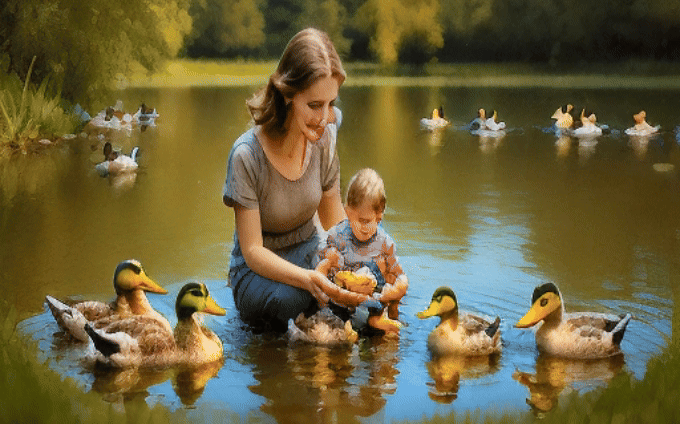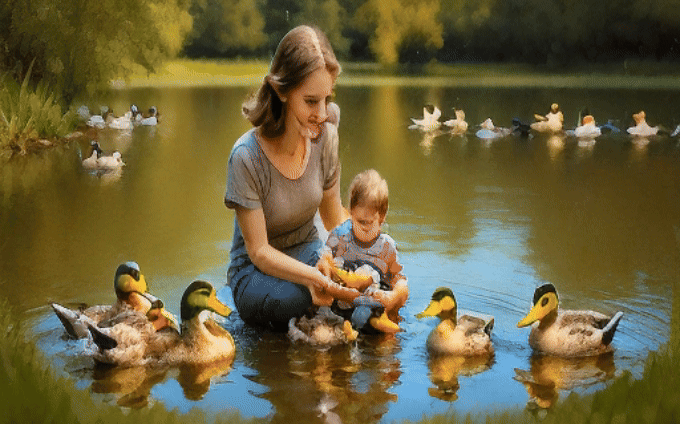








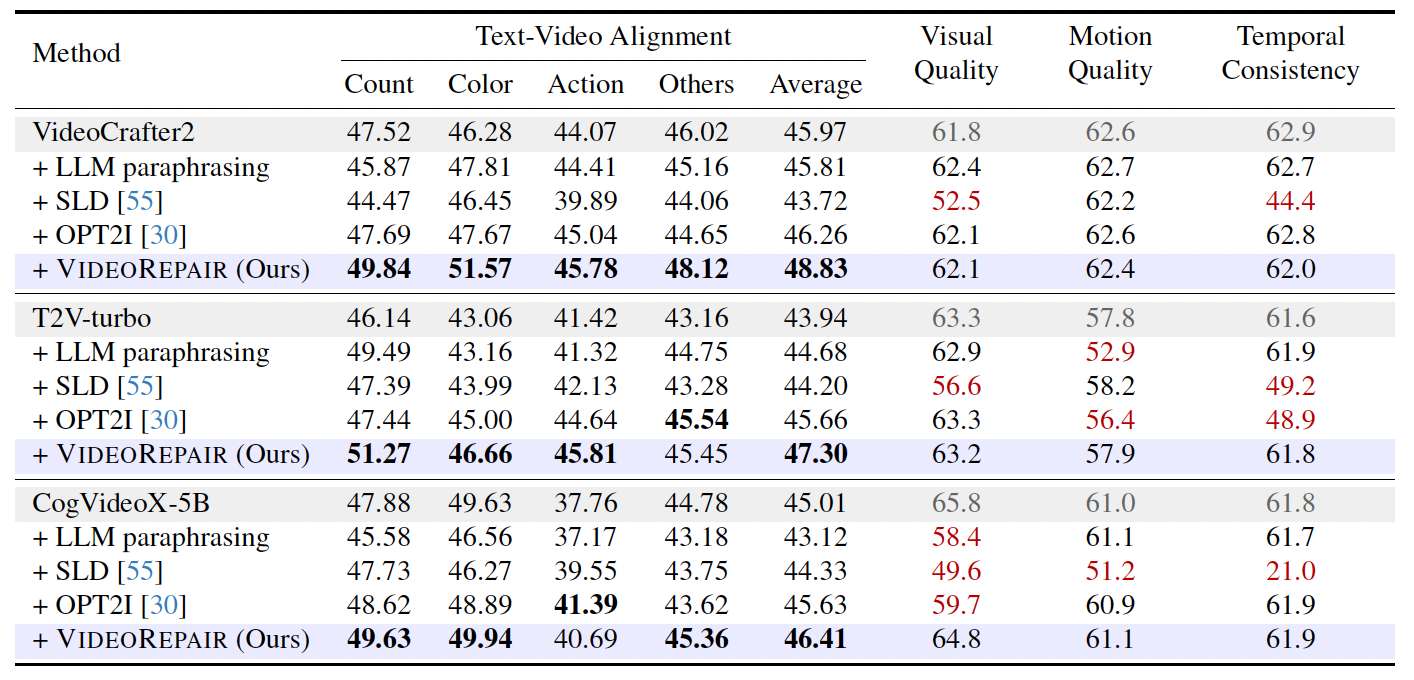
VideoRepair consistently outperforms all baselines across all four evaluation splits in text-video alignment, achieving relative gains of +6.22%, +7.65%, and +3.11% over VideoCrafter2, T2V-turbo, and CogVideoX-5B, respectively. We highlight the quality and consistency performance in red if it deteriorates by more than 1% from the original performance.
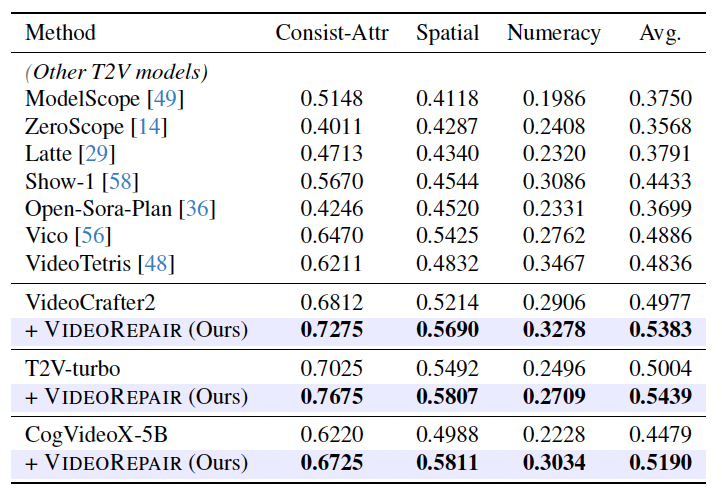
We observe that VideoRepair improves the initial videos from all T2V models (VideoCrafter2, T2V-turbo, and CogVideoX-5B) in all three splits, with relative improvements of +8.16%, +8.69%, and +15.87%, respectively.

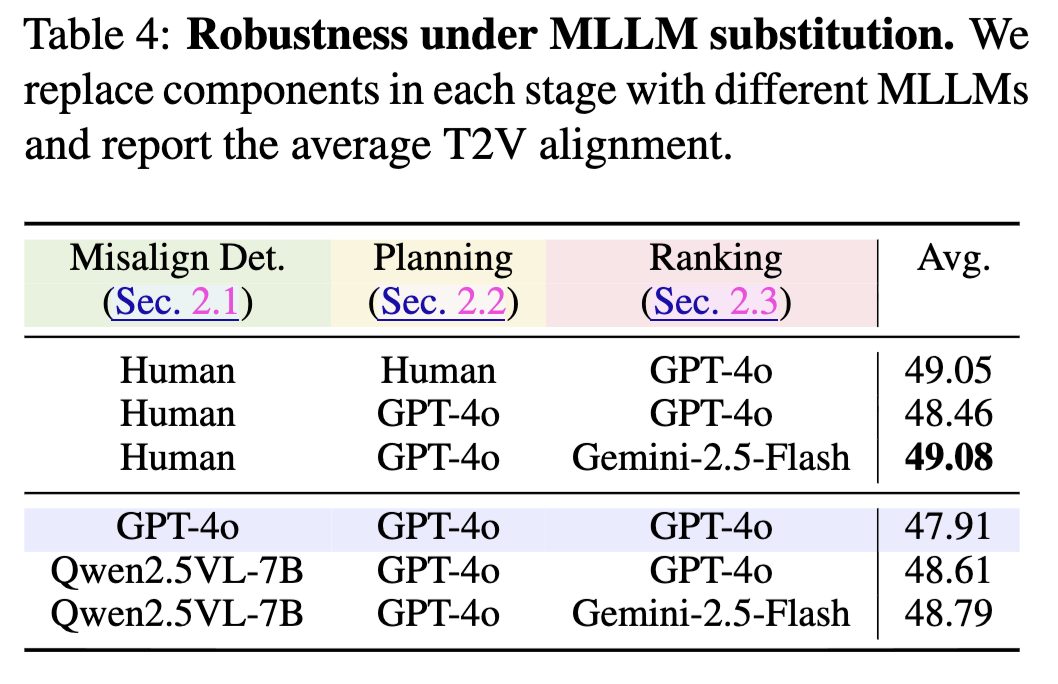
(Left) Ablations of VideoRepair components across evaluation question type, refinement planning strategy, and ranking metric. Our proposed configuration achieves the best overall alignment performance. (Right) Robustness analysis under MLLM substitution — replacing internal MLLM components with GPT-4o, Qwen2.5VL-7B, Gemini-2.5-Flash, and human annotations shows minimal performance variation, demonstrating the framework's modularity and flexibility.
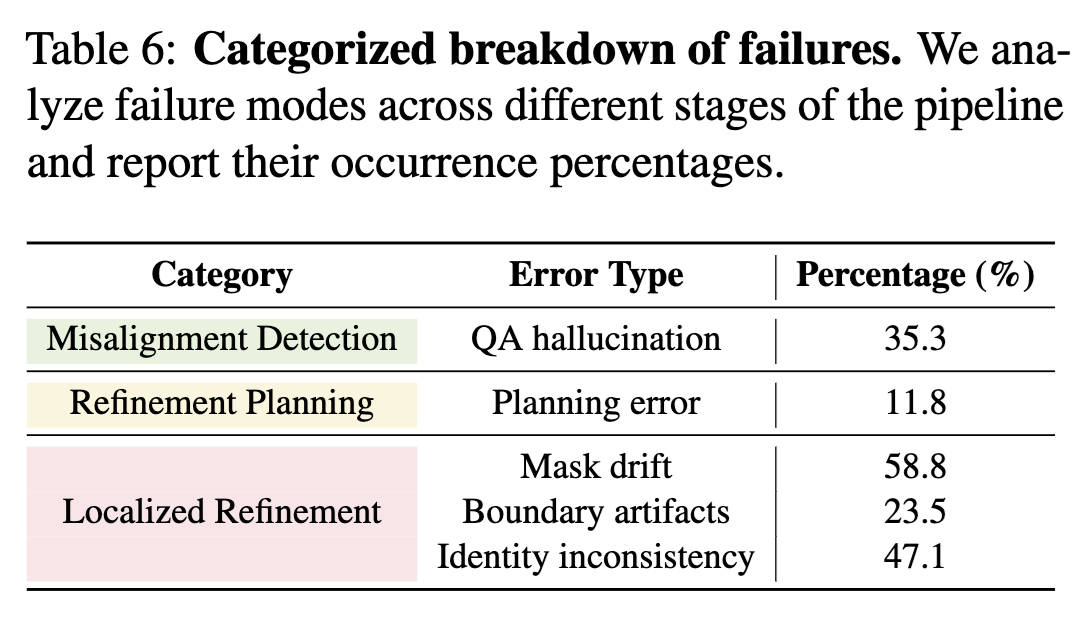
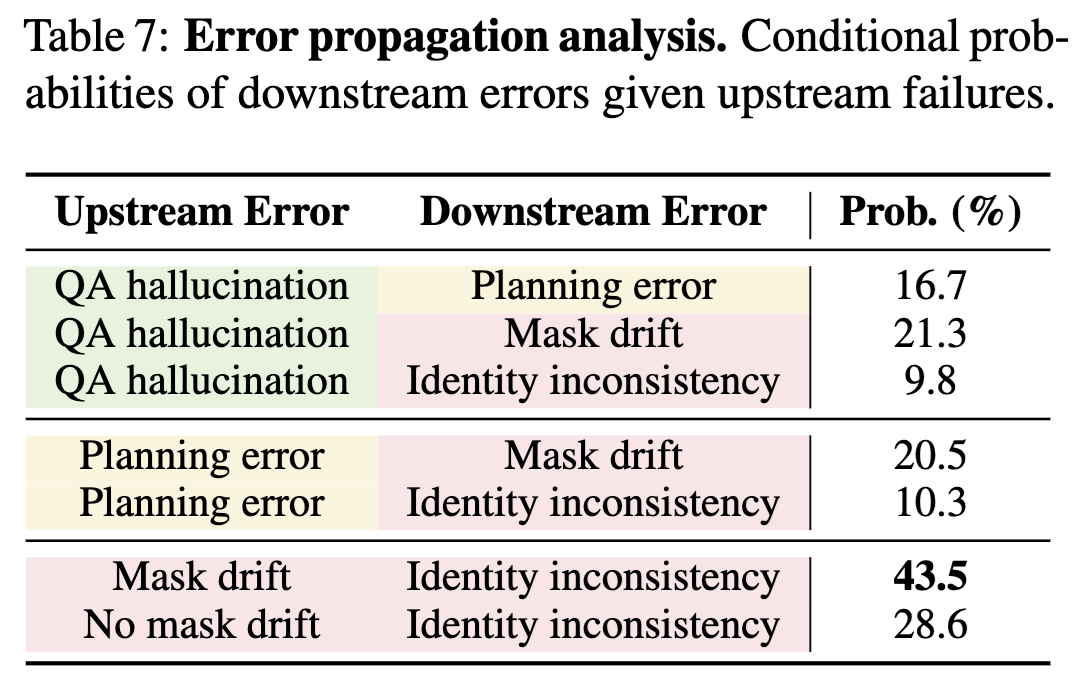
(Left) Categorized breakdown of failure modes: mask drift (58.8%) is the most frequent failure, followed by identity inconsistency (47.1%), QA hallucination (35.3%), boundary artifacts (23.5%), and planning error (11.8%). (Right) Error propagation analysis examining conditional probabilities of downstream errors given upstream failures. Mask drift shows the strongest cascading effect with 43.5% probability of causing identity inconsistencies, while QA hallucinations propagate weakly (9.8–21.3%).



